Опыт эксплуатации CEPH
T.me Когда данных становится больше, чем влезает на один диск, самое время задуматься о RAID. В детстве часто слышал от старших: «однажды RAID уйдут в прошлое, объектные хранилища заполонят мир, а ты даже не знаешь, что такое CEPH»,- поэтому первым делом в самостоятельной жизни стало создание своего кластера. Целью эксперимента было ознакомиться с внутренним устройством ceph и понять рамки его применения. Насколько оправдано внедрение ceph в средний бизнес, а в малый? После нескольких лет эксплуатации и пары необратимых потерь данных возникло понимание тонкостей, что не всё так однозначно. Особенности CEPH создают препятствия его широкому распространению, и из-за них эксперименты зашли в тупик. Ниже приводится описание всех пройденных шагов, полученный результат и сделанные выводы. Если знающие люди поделятся опытом и пояснят некоторые моменты — буду благодарен.
Примечание: комментаторы указали на серьёзные ошибки в некоторых допущениях, требующие пересмотра всей статьи.
Стратегия CEPH
Кластер CEPH объединяет произвольное количество K дисков произвольного размера и хранит данные на них, дублируя каждый кусочек (4 МБ по умолчанию) заданное число N раз.
Рассмотрим простейший случай с двумя одинаковыми дисками. Из них можно либо собрать RAID 1, либо кластер с N=2 — результат получится один и тот же. Если дисков три, и они разного размера, то собрать кластер с N=2 легко: часть данных будут на дисках 1 и 2, часть — на 1 и 3, а часть — на 2 и 3, тогда как RAID — нет (можно собрать такой RAID, но это будет извращением). Если дисков ещё больше, то возможно создание RAID 5, у CEPH есть аналог — erasure_code, который противоречит ранним концепциям разработчиков, и поэтому не рассматривается. RAID 5 предполагает, что имеется небольшое количество дисков, и все они в хорошем состоянии. При отказе одного, остальные должны продержаться до момента, пока не заменят диск и не будут восстановлены на него данные. CEPH же, при N>=3, поощряет использование старых дисков, в частности, если держать несколько хороших дисков для хранения одной копии данных, а оставшиеся две-три копии хранить на большом количестве старых дисков, то информация будет в сохранности, так как пока живы новые диски — проблем нет, а если один из них сломается, то одновременный отказ трёх дисков со сроком службы более пяти лет, желательно, из разных серверов — событие крайне маловероятное.
В распределении копий есть тонкость. По умолчанию подразумевается, что данные делятся на больше количество (
по 100 на диск) групп распределения PG, каждая из которых дублируется на каких-то дисках. Допустим, K=6, N=2, тогда при выходе из строя двух любых дисков, гарантированно теряются данные, так как по теории вероятности, найдётся хотя бы одна PG, которая расположится именно на этих двух дисках. А потеря одной группы делает недоступными все данные в пуле. Если же диски разбить на три пары и разрешить хранить данные только на дисках внутри одной пары, то такое распределение также устойчиво к отказу одного любого диска, зато при отказе двух вероятность потери данных не 100%, а всего 3/15, и даже при отказе трёх дисков — только 12/20. Отсюда, энтропия в распределении данных не способствует отказоустойчивости. Также заметим, что для файлового сервера свободная оперативная память значительно увеличивает скорость отклика. Чем больше памяти в каждом узле, и чем больше памяти во всех узлах — тем будет быстрее. Это несомненно преимущество кластера перед одиночным сервером и, тем более, аппаратным NAS-ом, куда встраивают очень малый объём памяти.
Отсюда следует, что CEPH — хороший способ с минимальными вложениями из устаревшего оборудования создать надёжную систему хранения данных на десятки ТБ с возможностью масштабирования (тут, конечно, потребуются затраты, но небольшие по сравнению с коммерческими СХД).
Реализация кластера
Для эксперимента возьмём списанный компьютер Intel DQ57TM + Intel core i3 540 + 16 ГБ ОЗУ. Четыре диска по 2 ТБ организуем в подобие RAID10, после успешного испытания добавим второй узел и ещё столько же дисков.
Устанавливаем Linux. От дистрибутива требуется возможность кастомизации и стабильность. Под требования подходят Debian и Suse. У Suse более гибкий установщик, позволяющий отключить любой пакет; к сожалению, я не смог понять, какие можно выкинуть без ущерба для системы. Ставим Debian через debootstrap buster. Опция min-base устанавливает нерабочую систему, в которой не хватает драйверов. Разница в размере по сравнению с полной версией не так велика, чтобы заморачиваться. Поскольку работа ведётся на физической машине, хочется делать снапшоты, как на виртуалках. Такую возможность предоставляет либо LVM, либо btrfs (или xfs, или zfs — разница не велика). У LVM снапшоты — не сильная сторона. Ставим btrfs. И загрузчик — в MBR. Нет смысла засорять диск 50 МБ разделом с FAT, когда можно затолкать его в 1 МБ область таблицы разделов и всё пространство выделить под систему. Заняло на диске 700 МБ. Сколько у базовой установки SUSE — не запомнил, кажется, около 1.1 или 1.4 ГБ.
Устанавливаем CEPH. Игнорируем версию 12 в репозитории debian и подключаем прямо с сайта 15.2.3. Следуем инструкции из раздела «устанавливаем CEPH вручную» со следующими оговорками:
Обзор кластера
ceph-osd — отвечает за хранение данных на диске. Для каждого диска запускается сетевая служба, которая принимает и исполняет запросы на чтение или запись в объекты. В этой статье рассматривается хранилище bluestore, как наиболее низкоуровневое. В каталоге службы создаются служебные файлы, описывающие ID кластера, хранилища, его тип итд, а также обязательный файл block — эти файлы не меняются. Если файл физический, то osd создаст в нём файловую систему и будет накапливать данные. Если файл является ссылкой, то данные будут в устройстве, на которое указывает ссылка. Помимо основного устройства могут быть дополнительно указаны block.db — метаданные (RocksDB) и block.wal — журнал (RocksDB write-ahead log). Если дополнительные устройства не указаны, то метаданные и журнал буду храниться в основном устройстве. Очень важно следить за наличием свободного места для RocksDB, в противном случае OSD не запустится!
При стандартном создании osd в старых версиях диск делится на два раздела: первый — 100 МБ xfs, монтируется в /var/lib/… и содержит служебную информацию, второй — отдаётся под основное хранилище. В новой версии используется lvm.
Теоретически, миниатюрный раздел можно не монтировать, а поместить файлы в /var/lib/. продублировав их на все узлы, а диск целиком выделить под данные, не создавая, ни GPT, ни LVM заголовка. При ручном добавлении OSD необходимо убедиться, что пользователь ceph имеет права на запись в блочные устройства с данными, и каталог с данными службы автоматически монтируется в /var/lib. если принято решение располагать их там. Желательно также указать параметр osd memory target, чтобы хватило физической памяти.
ceph-mds. На низком уровне CEPH — объектное хранилище. Возможность блочного хранения сводится к сохранению каждого блока 4МБ в виде объекта. По тому же принципу работает и файловое хранение. Создаётся два пула: один для метаданных, другой — для данных. Они объединяются в файловую систему. В этот момент создаётся какая-то запись, поэтому если удалить файловую систему, но сохранить оба пула, то восстановить её не получится. Есть процедура по извлечению файлов по блокам, не тестировал. За доступ к файловой системе отвечает служба ceph-mds. Для каждой файловой системы необходим отдельный экземпляр службы. Есть опция «ранг», которая позволяет создать подобие нескольких файловых систем в одной — тоже не тестировалось.
сeph-mon — эта служба хранит карту кластера. В неё входит информация обо всех OSD, алгоритм распределения PG в OSD и, самое главное, информация обо всех объектах (детали этого механизма мне непонятны: есть каталог /var/lib/ceph/mon/. /store.db, в нём лежит большой файл — 26МБ, а в кластере 105К объектов, получается чуть более 256 байт на объект,- я думаю, что монитор хранит список всех объектов и PG, в которых они лежат). Повреждение этого каталога приводит к потере всех данных в кластере. Отсюда и сделан вывод, что CRUSH показывает как PG расположены по OSD, а как объекты расположены по PG — в базе данных (вывод оказался неверным, что именно в ней содержится, требует уточнения). Как следствие, во-первых, мы не можем установить систему на флешку в режиме RO, так как в базу данных ведётся постоянная запись, необходим дополнительный диск под эти (вряд ли более 1 ГБ) данные, во-вторых, необходимо в реальном времени иметь копию этой базы. Если мониторов несколько, то отказоустойчивость обеспечивается за счёт них, но если монитор один, максимум — два, то необходимо обеспечить защиту данных. Есть теоретическая процедура восстановления монитора на основе данных OSD, на текущий момент получилось восстановить на объектном уровне, файловую систему на текущий момент не получилось восстановить. Пока что полагаться на этот механизм нельзя.
rados-gw — экспортирует объектное хранилище по протоколу S3 и подобные. Создаёт множество пулов, непонятно зачем. Особо не экспериментировал.
ceph-mgr — при установке этой службы запускаются несколько модулей. Один из них — не отключаемый autoscale. Он стремится поддерживать правильное количество PG/OSD. При желании управлять соотношением вручную, можно запретить масштабирование для каждого пула, но в таком случае модуль падает с делением на 0, и статус кластера становится ERROR. Модуль написан на питоне, и если закомментировать в нём нужную строчку, это приводит к его отключению. Детали лень вспоминать.
Резюме
Варианты дальнейших действий: отказаться от CEPH и воспользоваться банальным много-дисковым btrfs (или xfs, zfs), узнать новую информацию о CEPH, которая позволит эксплуатировать его в указанных условиях, попробовать в качестве повышения квалификации написать собственное хранилище.
Источник
Пять вопросов о Ceph с пояснениями
Что нужно знать о Ceph, хранилище с открытым исходным кодом, чтобы решить, подходит ли оно вашей компании. В статье будет сравнение с альтернативными объектными хранилищами, а также рассмотрена оптимизация Ceph.
Хранилище Ceph — одно из наиболее популярных объектных хранилищ. Это высокомасштабируемое и унифицированное хранилище с открытым исходным кодом также обладает некоторыми преимуществами.
Ceph предлагает функции, которые, в принципе, есть в других хранилищах для предприятий, но он, вероятно, будет дешевле, чем обычный SAN. Для Ceph с открытым исходным кодом не нужны лицензионные отчисления, которые есть у проприетарных систем. Также у Ceph нету зависимости от дорогого специализированного оборудования, он может быть установлен на обычное оборудование.
Среди других преимуществ — масштабируемость и гибкость. Ceph предлагает несколько интерфейсов доступа к хранилищу: объектный, блочный и файловый. Для увеличения емкости системы достаточно добавить больше серверов.
К некоторым недостаткам при использовании Ceph можно отнести нужду в быстрой, а значит более дорогой сети. Это также не бесплатно для любой компании. Если вы используете его для хранения важных данных — скорее всего вы используете один из двух коммерческих вариантов с поддержкой от RedHat или SUSE. Несмотря на это, Ceph — это более дешёвая и живучая альтернатива проприетарным SAN.
Какое объектное хранилище лучше: Ceph или Swift?
Ceph и Swift — объектные хранилища, распределяющие и реплицирующие данные по кластеру. Они используют файловую систему XFS или другую файловую систему, доступную в Linux. Они оба разработаны для масштабирования, так что пользователи могут легко добавить узлы хранилища.
Но что касается доступа к данным, то Swift разработан с прицелом на облака, использует RESTful API. Приложения могут няпрямую получить доступ к Swift, обходя при этом операционную систему. Это хорошо в облачном окружении, но усложняет доступ к хранилищу Swift.
Ceph — более гибкое объектное хранилище с четырьмя способами доступа: Amazon S3 RESTful API, CephFS, Rados Block Device и шлюзом iSCSI. Ceph и Swift также отличаются способом доступа клиентов. Так в Swift клиенты должны идти через Swift Gateway, который сам по себе является единой точкой отказа. Ceph с другой стороны использует устройство объектного хранилища, доступное на каждом узле. Другая часть, используемая для доступа к объектному хранилищу, запускается на клиенте. Так что здесь Ceph более гибкий.
Данные, хранимые в Ceph, обычно целостные по всему кластеру. В принципе это справедливо и для данных в Swift, но для синхронизации кластера может потребоваться время. С учетом этой разницы Ceph неплохо работает в пределах одного датацентра, работая с данными, которым надо высокий уровень целостности, например виртуальные машины и базы данных. Swift лучше подходит для больших окружений, работающих с огромными объемами данных.
Какая разница между Ceph и GlusterFS?
GlusterFS и Ceph — системы хранения данных с открытым исходным кодом, отлично работающими в облачных окружениях. Обе могут легко внедрять новые устройства хранения в существующую инфраструктуру хранения, используют репликацию для отказоустойчивости, а также работают на обычном оборудовании. В обеих системах доступ к метаданным децентрализован, подразумевая отсутствие единой точки отказа.
Несмотря на наличие общих вещей, у них есть также ключевые различия. GlusterFS — файловая система Linux, которую легко внедрить в окружении Linux, но нельзя так же легко внедрить в окружении Windows.
Ceph с другой стороны предоставляет высокомасштабируемое объектное, файловое и блочное хранилище в единой унифицированной системе. Как и в любом другом объектном хранилище, приложения пишут в хранилище с помощью API, минуя операционную систему. С учетом этого, хранилища Ceph внедряются одинаково легко как в Linux, так и в Windows. Из-за этого, а также по другим причинам, Ceph — лучший выбор для разнородных окружений, где используются Linux и другие операционные системы.
Если сравнивать по скорости работы, то и Ceph и GlusterFS работают примерно одинаково. Также GlusterFS по большей части ассоциируется с RedHat, в то же время Ceph шире поддерживается сообществом.
Ceph с открытым исходным кодом или коммерческая версия Ceph: как их сравнивать?
Пользователи могут без каких либо выплат сделать любую SDS на основе Ceph, пока его исходный код остается открытым. Ceph предлагает руководства по запуску, в котором описаны все этапы по его сборке в любом дистрибутиве Linux, а также настройке окружения Ceph.
Это достаточно сложный процесс, требующий определенного опыта. Тут и появляются коммерческие сборки Ceph, их проще сделать, кроме сборок также предоставляется и поддержка.
Есть два коммерческих продукта: RedHat Ceph Storage и SUSE Enterprise Storage. Есть некоторые различия, так компания SUSE разработала iSCSI Gateway, позволяющий пользователям получить доступ к хранилищу Ceph. RedHat внедрила Ceph-Ansible, инструмент управления настройками, с которым Ceph относительно легче устанавливать и настраивать.
Какие способы улучшения производительности Ceph лучшие?
Для хорошей производительности достаточно SATA дисков. Алгоритм CRUSH (Controlled Replication Under Scalable Hashing) в Ceph решает, где хранить данные в хранилище. Он разработан для гарантии быстрого доступа к хранилищу. Однако для оптимальной скорости Ceph надо 10G сеть, а лучше — 40G.
Несколько больших серверов, на которых установлено много дисков, обеспечат наилучшую производительность, однако диск с журналом должен быть на отдельном устройстве. Использование журнала на SSD обеспечит максимальную скорость, а файловая система Btrfs даст оптимальную производительность Ceph.
Как вы внедряете Ceph на Windows?
Есть два способа внедрения: Ceph Gateway и iSCSI target в SUSE Enterprise Storage. Ceph Gateway обеспечивает приложениям доступ с помощью RESTful API, но это не самый лучший способ предоставления доступа для операционной системы.
Ceph может быть настроен как и любая другая СХД на основе iSCSI с помощью iSCSI target в SUSE Enterprise Storage. Это дает доступ к хранилищу для операционной системы с поддержкой iSCSI initiator, к примеру серверной Windows.
Курс по Ceph будет запущен образовательным центром Слёрм 15 октября 2020. Cейчас можно сделать предзаказ с существенной скидкой.
№1: Что такое Ceph и чем он не является
Источник
Ceph: Cloud Storage без компромиссов
Здравствуйте, уважаемые читатели!
Мы решили рассказать об этом замечательном продукте, который используется в CERN, 2GIS, Mail.ru и в нашем облачном хостинге.
Что такое Ceph?
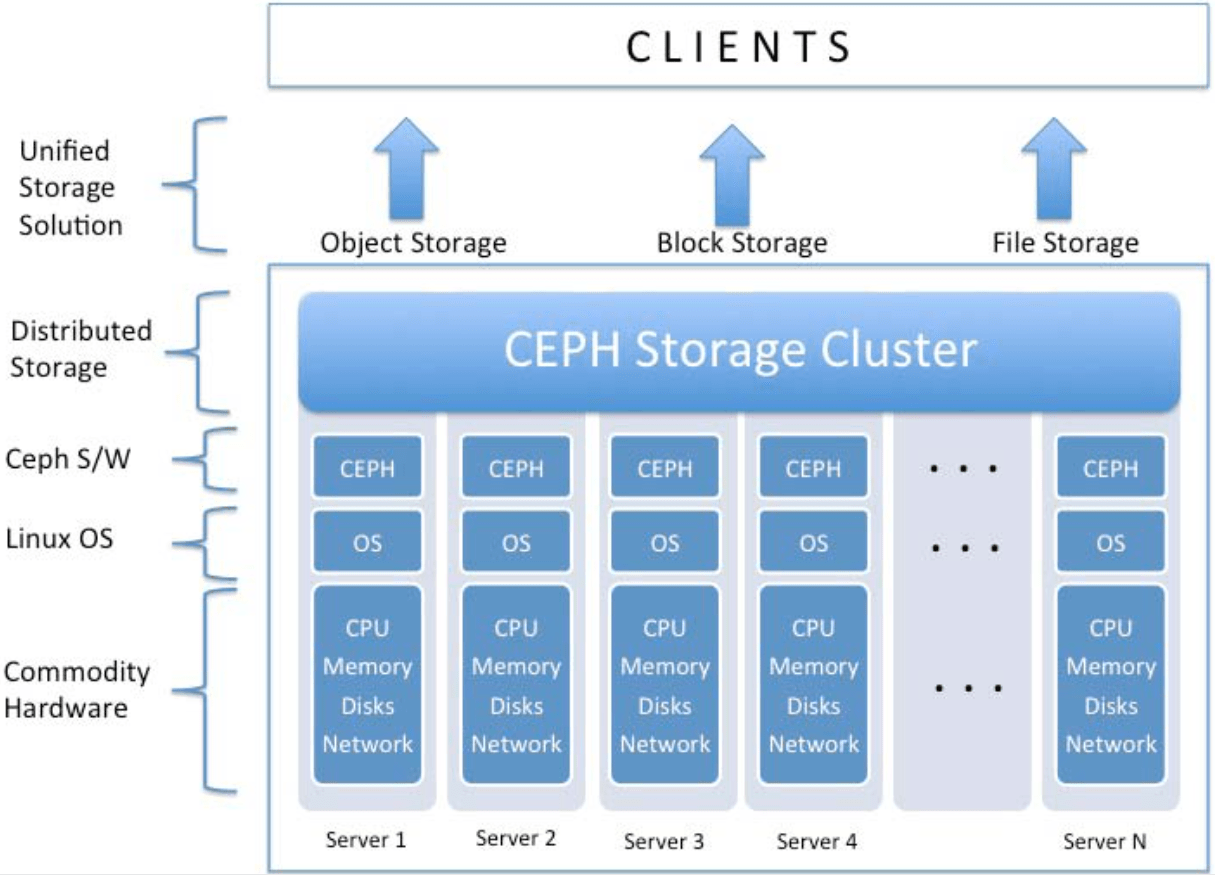
Ceph — отказоустойчивое распределенное хранилище данных, работающее по протоколу TCP. Одно из базовых свойств Ceph — масштабируемость до петабайтных размеров. Ceph предоставляет на выбор три различных абстракции для работы с хранилищем: абстракцию объектного хранилища (RADOS Gateway), блочного устройства (RADOS Block Device) или POSIX-совместимой файловой системы (CephFS).
Абстракция объектного хранилища
Абстракция объектного хранилища (RADOS Gateway, или RGW) вкупе с FastCGI-сервером позволяет использовать Ceph для хранения пользовательских объектов и предоставляет API, совместимый с S3/Swift. На Хабре уже была статья о том, как по-быстрому настроить Ceph и RGW. В режиме объектного хранилища Ceph давно и успешно используется в продакшене у ряда компаний.
Абстракция блочного устройства
Абстракция блочного устройства (в оригинале — RADOS Block Device, или RBD) предоставляет пользователю возможность создавать и использовать виртуальные блочные устройства произвольного размера. Программный интерфейс RBD позволяет работать с этими устройствами в режиме чтения/записи и выполнять служебные операции — изменение размера, клонирование, создание и возврат к снимку состояния итд.
Гипервизор QEMU содержит драйвер для работы с Ceph и обеспечивает виртуальным машинам доступ к блочным устройствам RBD. Поэтому Ceph сейчас поддерживается во всех популярных решениях для оркестровки облаков — OpenStack, CloudStack, ProxMox. RBD также готов к промышленному использованию.
Абстракция POSIX-совместимой файловой системы
CephFS — POSIX-совместимая файловая система, использующая Ceph в качестве хранилища. Несмотря на то, что CephFS не является production-ready и пока не имеет значимого промышленного применения, здесь на Хабре уже есть инструкция по ее настройке.
Терминология
Ниже перечислены основные сущности Ceph.
Metadata server (MDS) — вспомогательный демон для обеспечения синхронного состояния файлов в точках монтирования CephFS. Работает по схеме активная копия + резервы, причем активная копия в пределах кластера только одна.
Mon (Monitor) — элемент инфраструктуры Ceph, который обеспечивает адресацию данных внутри кластера и хранит информацию о топологии, состоянии и распределении данных внутри хранилища. Клиент, желающий обратиться к блочному устройству rbd или к файлу на примонтированной cephfs, получает от монитора имя и положение rbd header — специального объекта, описывающего положение прочих объектов, относящихся к запрошенной абстракции (блочное устройство или файл) и далее общается со всеми OSD, участвующими в хранении файла.
Объект (Object) — блок данных фиксированного размера (по умолчанию 4 Мб). Вся информация, хранимая в Ceph, квантуется такими блоками. Чтобы избежать путаницы подчеркнем — это не пользовательские объекты из Object Storage, а объекты, используемые для внутреннего представления данных в Ceph.
OSD (object storage daemon) — сущность, которая отвечает за хранение данных, основной строительный элемент кластера Ceph. На одном физическом сервере может размещаться несколько OSD, каждая из которых имеет под собой отдельное физическое хранилище данных.
Карта OSD (OSD Map) — карта, ассоциирующая каждой плейсмент-группе набор из одной Primary OSD и одной или нескольких Replica OSD. Распределение placement groups (PG) по нодам хранилища OSD описывается срезом карты osdmap, в которой указаны положения всех PG и их реплик. Каждое изменение расположения PG в кластере сопровождается выпуском новой карты OSD, которая распространяется среди всех участников.
Плейсмент-группа (Placement Group, PG) — логическая группа, объединяющая множество объектов, предназначенная для упрощения адресации и синхронизации объектов. Каждый объект состоит лишь в одной плейсмент группе. Количество объектов, участвующих в плейсмент-группе, не регламентировано и может меняться.
Primary OSD — OSD, выбранная в качестве Primary для данной плейсмент-группы. Клиентское IO всегда обслуживается той OSD, которая является Primary для плейсмент группы, в которой находится интересующий клиента блок данных (объект). Primary OSD в асинхронном режиме реплицирует все данные на Replica OSD.
RADOS Gateway (RGW) — вспомогательный демон, исполняющий роль прокси для поддерживаемых API объектных хранилищ. Поддерживает географически разнесенные инсталляции (для разных пулов, или, в представлении Swift, регионов) и режим active-backup в пределах одного пула.
Replica OSD (Secondary) — OSD, которая не является Primary для данной плейсмент-группы и используется для репликации. Клиент никогда не общается с ними напрямую.
Фактор репликации (RF) — избыточность хранения данных. Фактор репликации является целым числом и показывает, сколько копий одного и того же объекта хранит кластер.
Архитектура Ceph
Основных типов демонов в Ceph два — мониторы (MON) и storage-ноды (OSD). RGW и MDS демоны не участвуют в распределении данных, являясь вспомогательными сервисами. Мониторы объединяются в кворум и общаются по PAXOS-подобному протоколу. Собственно, кластер является работоспособным до тех пор, пока в нем сохраняется большинство участников сконфигурированного кворума, то есть при ситуации split-brain посередине и четном количестве участников «выживет» только одна часть, поскольку предыдущие выборы в PAXOS автоматически уменьшили число активных участников до нечетного числа. При потере большинства кворума кластер «замораживается» для любых операций, предотвращая возможное рассогласование записанных или прочитанных данных до восстановления минимального кворума.
Восстановление и перебалансировка данных
Потеря из вида одной из копий объекта приводит к переходу объекта и содержащей его плейсмент-группы в состояние degraded и выпуску новой карты OSD (osdmap). Новая карта содержит новое расположение потерянной копии объекта и, если через заданное время утраченная копия не вернется, недостающая копия будет восстановлена в другом месте, чтобы сохранить число копий, определяемое фактором репликации. Операции, выполнявшиеся в момент подобной ошибки, автоматически переключатся на одну из доступных копий. В худшем случае их задержка будет измеряться единицами секунд.
Важным свойством Ceph является то, что все операции по перебалансировке кластера происходят в фоновом режиме одновременно с пользовательским I/O. Если клиент обращается к объекту, который находится в recovering состоянии, Ceph вне очереди восстановит объект и его копии, а затем выполнит запрос клиента. Такой подход обеспечивает минимальное латенси I/O даже тогда, когда восстановление кластера идет полным ходом.
Распределение данных в кластере
Одна из самых важных особенностей Ceph — возможность тонкой настройки репликации, задаваемой правилами CRUSH — мощного и гибкого механизма, базирующегося на случайном распределении PG по группе OSD с учетом правил (вес, состояние ноды, запрет на размещение в той же группе нод). По умолчанию OSD имеют вес, базирующийся на величине свободного места в соответствующей точке монтирования в момент ввода OSD в кластер и подчиняются правилу распределения данных, запрещающему держать две копии одной PG на одной ноде. CRUSHMAP — описание распределения данных — может быть модифицирован под правила, запрещающие держать вторую копию в пределах одной стойки, тем самым обеспечивая отказоустойчивость на уровне вылета целой стойки.
Теоретически, подобный подход позволяет осуществлять в том числе гео-репликацию в реальном времени, однако на практике это можно использовать лишь в режиме Object Storage, поскольку в режимах CephFS и RBD задержки операций будут слишком велики.
Альтернативы и преимущества Ceph
Наиболее качественной и близкой по духу свободной кластерной ФС являются GlusterFS. Она поддерживается RedHat и имеет некоторые преимущества (например, локализует Primary копию данных рядом с клиентом). Однако наши тесты показали некоторое отставание GlusterFS в смысле производительности и плохую отзывчивость при перестроении. Другие серьезные минусы — отсутствие CoW (в том числе и в прогнозируемом будущем) и низкая активность сообщества.
Преимущество Ceph перед прочими кластерными системами хранения данных состоит в отсутствии единых точек отказа и в практически нулевой стоимости обслуживания при восстановительных операциях. Избыточность и устойчивость к авариям заложена на уровне дизайна и достается даром.
Возможные замены подразделяются на два типа — кластерные фс для суперкомпьютеров(GPFS/Lustre/etc.) и дешевые централизованные решения вроде iSCSI или NFS. Первый тип достаточно сложен в обслуживании и не заточен на эксплуатацию в условиях отказавшего оборудования — «замораживание» ввода-вывода, особенно чувствительное при экспорте точки монтирования в вычислительную ноду, не позволяет использовать подобные фс в публичном сегменте. Минусы «классических» решений довольно хорошо понятны — отсутствие масштабируемости и необходимость закладывать топологию для failover на уровне железа, что приводит к увеличению стоимости.
С Ceph восстановление и перестроение кластера происходят действительно незаметно, практически не влияя на клиентское I/O. То есть деградировавший кластер для Ceph — это не экстраординарная ситуация, а всего лишь одно из рабочих состояний. Насколько нам известно, ни одна другая открытая программная СХД не имеет этого свойства, достаточного для ее использования в публичном облаке, где запланированное прекращение обслуживания невозможно.
Производительность
Цели и результаты
Два года назад Ceph подкупил нас своими впечатляющими возможностями. Хотя многие из них на тот момент работали совсем не идеально, мы приняли решение строить облако именно на нем. В последующие месяцы мы столкнулись с рядом проблем, доставивших нам немало неприятных минут.
Например, сразу после публичного релиза год назад мы обнаружили, что перестроение кластера влияет на его отзывчивость больше, чем хотелось бы. Или что определенный вид операций приводит к существенному увеличению латенси последующих операций. Или что в определенных (к счастью, редких) условиях клиентская виртуальная машина может намертво зависнуть на I/O. Так или иначе, багфикс длительностью в полгода сделал свое дело, и на сегодняшний день мы абсолютно уверены в нашей СХД. Ну а в процессе устранения трудностей мы обзавелись целым рядом инструментов отладки и мониторинга. Один из них — мониторинг длительности всех без исключения операций с блочными устройствами (на данный момент кластер ежесекундно обслуживает несколько тысяч операций чтения/записи). Вот так сегодня выглядит отчет о латенси в нашей админ-панели:
Зеленым на графике отмечена минимальная длительность операций, красным — максимальная, бирюзовым — медиана. Впечатляет, не правда ли?
Хотя система хранения данных уже давно абсолютно стабильна, эти инструменты по-прежнему помогают нам в решении повседневных задач и заодно цифрами подтверждают отличное качество нашего сервиса.
Если вы используете выделенный хостинг в своей работе — предлагаем вам попробовать наши услуги в действии и оценить, какие преимущества дает Ceph. Платить ничего не нужно — двухнедельный пробный период и тестовый баланс в 500 рублей вы сможете активировать сразу после регистрации.
В следующих постах мы рассмотрим практическую сторону использования Ceph, расскажем о фичах, которые появились у нас за последний год (а их немало) и остановимся подробнее на преимуществах, которые дает использование SSD.
Источник: https://neuroplus.ru/ceph-chto-eto-takoe.html